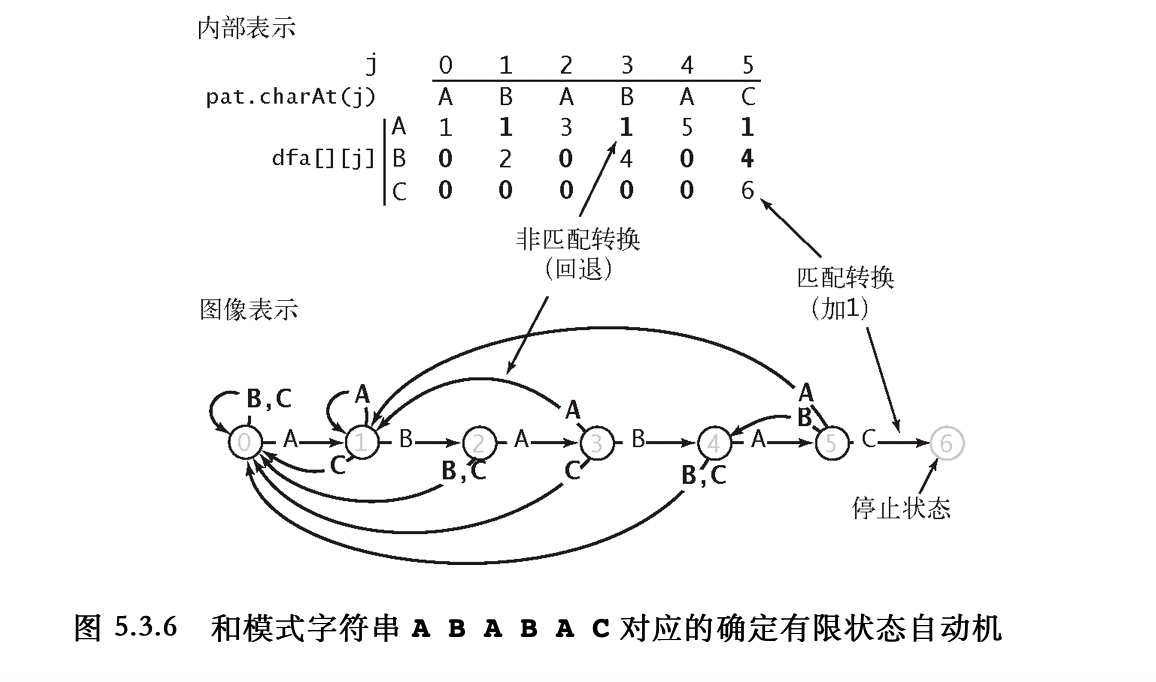
树状数组上的二分
题目大意,给你 n n n a x = d a_x = d a x = d T , T ∈ [ 0 , n ] T, T \in [0, n] T , T ∈ [ 0 , n ] ∑ i = 1 T a i ⩽ s \displaystyle \sum_{i = 1}^{T} a_i \leqslant s i = 1 ∑ T a i ⩽ s
树状数组二分算法描述如下,从高位往低位 去遍历树状数组pos \text{pos} pos C [ ⋯ ] C[\cdots] C [ ⋯ ] t t t
for j ∈ ⌈ log n ⌉ → 0 \displaystyle \textbf{for} \quad j \in \left\lceil \log n\right\rceil \to 0 for j ∈ ⌈ log n ⌉ → 0 p o s ′ ← p o s + 2 j \displaystyle \quad pos' \leftarrow pos + 2^j p o s ′ ← p o s + 2 j if t + C [ p o s ′ ] ⩽ s : p o s ← p o s ′ , t + = C [ p o s ′ ] \displaystyle \quad \textbf{if} \quad t + C[pos'] \leqslant s: pos \leftarrow pos', t += C[pos'] if t + C [ p o s ′ ] ⩽ s : p o s ← p o s ′ , t + = C [ p o s ′ ]
算法实现原理 p o s pos p o s j j j j j j 0 0 0 p o s : ? ? ? 0 0 ⋯ 0 pos:\quad ?\ ?\ ? \ 0 \ 0\cdots 0 p o s : ? ? ? 0 0 ⋯ 0 p o s ′ ← p o s + 2 j pos' \leftarrow pos + 2^j p o s ′ ← p o s + 2 j j j j 1 1 1 p o s ′ : ? ? ? 1 0 ⋯ 0 pos': \quad ?\ ? \ ? \ 1 \ 0 \cdots 0 p o s ′ : ? ? ? 1 0 ⋯ 0 C [ p o s ′ ] C[pos'] C [ p o s ′ ] [ ( ? ? ? 0 0 ⋯ 1 ) → ( ? ? ? 1 0 ⋯ 0 ) ] [(? \ ? \ ? \ 0 \ 0 \cdots 1 ) \to ( ? \ ? \ ? \ 1 \ 0 \cdots 0)] [ ( ? ? ? 0 0 ⋯ 1 ) → ( ? ? ? 1 0 ⋯ 0 ) ]
换句话说,C [ p o s ′ ] C[pos'] C [ p o s ′ ] [ p o s + 1 ⋯ p o s ′ ] [pos+1\cdots pos'] [ p o s + 1 ⋯ p o s ′ ] p o s ′ pos' p o s ′ s s s
二维树状数组
与一维类似,二维树状数组的 C ( i , j ) C(i, j) C ( i , j ) a ( [ i − lowbit ( i ) + 1 ⋯ i ] , [ j − lowbit ( j ) + 1 ⋯ j ] ) \displaystyle a([i-\text{lowbit}(i)+1\cdots i], [j - \text{lowbit}(j)+1 \cdots j]) a ( [ i − lowbit ( i ) + 1 ⋯ i ] , [ j − lowbit ( j ) + 1 ⋯ j ] ) for \text{for} for
线段树维护最大子段和
带区间修改的最大子段和维护,可以用线段树p p p mss \text{mss} mss
那么它的最大子段只可能来自 3 3 3
mss = max ( l . mss , r . mss , l . msuf + r . mpre ) \text{mss} = \max(l.\text{mss}, \quad r.\text{mss}, \quad l.\text{msuf} + r.\text{mpre}) mss = max ( l . mss , r . mss , l . msuf + r . mpre ) msuf , mpre \text{msuf}, \text{mpre} msuf , mpre
msuf = max ( r . msuf , r . s u m + l . msuf ) \text{msuf} = \max(r.\text{msuf}, \quad r.sum + l.\text{msuf}) msuf = max ( r . msuf , r . s u m + l . msuf ) mpre = max ( l . mpre , l . s u m + r . mpre ) \text{mpre} = \max(l.\text{mpre}, \quad l.sum + r.\text{mpre}) mpre = max ( l . mpre , l . s u m + r . mpre ) s u m = l . s u m + r . s u m sum = l.sum + r.sum s u m = l . s u m + r . s u m
这些信息分别维护出来就可以
线段树懒标记编程技巧
线段树处理懒标记的时候,应该让标记尽量少3 3 3 + d +d + d × d \times d × d d d d
那么可以考虑将这三种操作统一起来
假设用一个标记 tag ( a , b ) \textbf{tag}(a, b) tag ( a , b ) tag ⋅ x \textbf{tag} \cdot x tag ⋅ x tag \textbf{tag} tag x x x x ← x ⋅ a + b x \leftarrow x \cdot a + b x ← x ⋅ a + b
这样区间 + d +d + d tag ( 1 , d ) \textbf{tag}(1, d) tag ( 1 , d ) × d \times d × d tag ( d , 0 ) \textbf{tag}(d, 0) tag ( d , 0 ) d d d tag ( 0 , d ) \textbf{tag}(0, d) tag ( 0 , d )
接着考虑两件事情,分别是标记合并和信息更新p p p tag ( a , b ) \textbf{tag}(a, b) tag ( a , b ) x ← x ⋅ a + b x \leftarrow x \cdot a + b x ← x ⋅ a + b
( ∑ x ) a + p . s z × b \displaystyle \left(\sum x \right) a + p.sz \times b ( ∑ x ) a + p . s z × b s u m ← s u m ⋅ a + p . s z × b sum \leftarrow sum \cdot a + p.sz \times b s u m ← s u m ⋅ a + p . s z × b
考虑标记合并,假设当前两个标记 tg1 ( a 1 , b 1 ) , tg2 ( a 2 , b 2 ) \text{tg1}(a_1, b_1), \text{tg2}(a_2, b_2) tg1 ( a 1 , b 1 ) , tg2 ( a 2 , b 2 ) 不能交换 的tg1 ( a 1 , b 1 ) \text{tg1}(a_1, b_1) tg1 ( a 1 , b 1 ) tg2 ( a 2 , b 2 ) \text{tg2}(a_2, b_2) tg2 ( a 2 , b 2 )
x ← ( x × a 1 + b 1 ) × a 2 + b 2 x \leftarrow (x \times a_1 + b_1) \times a_2 + b_2 x ← ( x × a 1 + b 1 ) × a 2 + b 2 x ← x × ( a 1 ⋅ a 2 ) + b 1 ⋅ a 2 + b 2 x \leftarrow x \times (a_1 \cdot a_2) + b_1 \cdot a_2 + b_2 x ← x × ( a 1 ⋅ a 2 ) + b 1 ⋅ a 2 + b 2 tg ( a 1 ⋅ a 2 , b 1 ⋅ a 2 + b 2 ) \text{tg}(a_1 \cdot a_2, \quad b_1 \cdot a_2 + b_2) tg ( a 1 ⋅ a 2 , b 1 ⋅ a 2 + b 2 )
最后注意的是,标记清空的标志是 t a g = tag ( 1 , 0 ) tag = \textbf{tag}(1, 0) t a g = tag ( 1 , 0 ) tag ( 1 , 0 ) \textbf{tag}(1, 0) tag ( 1 , 0 )
线段树上二分
问题描述,给你一个序列,支持单点修改,能够修改 a x = d a_x = d a x = d q q q [ l , r ] [l, r] [ l , r ] 第一个 ⩾ d \geqslant d ⩾ d p o s pos p o s − 1 -1 − 1
可以用线段树维护一个区间最大值 m a x v maxv m a x v [ l , r ] [l, r] [ l , r ]
如果线段树当前区间和 [ l , r ] [l, r] [ l , r ] m a x v < d maxv < d m a x v < d ⩾ d \geqslant d ⩾ d − 1 -1 − 1 p o s pos p o s 优先去左边找,左边没有就去右边找
如果当前区间 l = r l = r l = r l l l 继续递归 l . m a x v ⩾ d l.maxv \geqslant d l . m a x v ⩾ d 递归左儿子 ,返回 search ( p ≪ 1 , l , m i d , d ) \text{search}(p\ll 1, l, mid, d) search ( p ≪ 1 , l , m i d , d ) search ( p ≪ 1 + 1 , m i d + 1 , r , d ) \text{search}(p \ll 1+1, mid+1, r, d) search ( p ≪ 1 + 1 , m i d + 1 , r , d )
如果当前区间需要分裂 ,同时递归左右子树,那么先递归左子树p o s = search ( p ≪ 1 , l , m i d , d ) pos = \text{search}(p \ll 1, l, mid, d) p o s = search ( p ≪ 1 , l , m i d , d ) p o s ≠ − 1 pos \neq -1 p o s = − 1 p o s pos p o s search ( p ≪ 1 + 1 , m i d + 1 , r , d ) \text{search}(p \ll 1 + 1, mid+1, r, d) search ( p ≪ 1 + 1 , m i d + 1 , r , d )
动态开点线段树
NOIP2017 列队
算法分析 n × m n \times m n × m ( x , y ) (x, y) ( x , y )
找到标号第 x x x y y y ( x , y ) (x, y) ( x , y ) [ y + 1 ⋯ m ] [y+1\cdots m] [ y + 1 ⋯ m ]
然后操作第 m m m m m m [ x + 1 ⋯ n ] [x+1\cdots n] [ x + 1 ⋯ n ]
最后把取出来的元素插入 ( n , m ) (n, m) ( n , m )
注意到我们需要对 n n n m m m 前缀第 k k k n + 1 n+1 n + 1 [ 1 ⋯ n ] [1\cdots n] [ 1 ⋯ n ] [ 1 → n ] [1 \to n] [ 1 → n ] n + 1 n+1 n + 1 m m m
将线段树写成动态开点 ,这样就可以尝试维护操作了,维护区间内被删除了多少个数 c n t cnt c n t
对于删除 ( x , y ) (x, y) ( x , y ) x x x t r ( x ) tr(x) t r ( x ) y y y p p p p p p i d = ( x − 1 ) ⋅ m + p id = (x-1)\cdot m + p i d = ( x − 1 ) ⋅ m + p 懒惰删除 的方法,对线段树这个点标记为删除,即 u . cnt + 1 u.\text{cnt} + 1 u . cnt + 1
值得注意的是,懒惰删除的时候,和一般线段树不一样,我们 pull ( u ) \text{pull}(u) pull ( u ) u u u 加判一下子树存在 u . l ≠ null u.l \neq \text{null} u . l = null u . cnt + = u . l . cnt u.\text{cnt} += u.l.\text{cnt} u . cnt + = u . l . cnt u . cnt + = 0 u.\text{cnt} += 0 u . cnt + = 0
修改的时候,比如要出列第 y y y r o o t → y root \to y r o o t → y 递归子树的时候 ,如果子树是 null \textbf{null} null new \textbf{new} new
接着考虑查询第 k k k null \textbf{null} null new \textbf{new} new ( u , l , r ) (u, l, r) ( u , l , r ) t o t = m i d − l + 1 tot = mid - l + 1 t o t = m i d − l + 1 t o t tot t o t t o t − = u . l . cnt tot -= u.l.\text{cnt} t o t − = u . l . cnt 左子树对应的区间我们没有修改过 ,自然对应的 cnt = 0 \text{cnt} = 0 cnt = 0
然后执行很常见的二分查找逻辑,如果 k ⩽ t o t k \leqslant tot k ⩽ t o t k k k k − t o t k - tot k − t o t
综上所述
通过线段树维护,可以得到要出列的点编号,假设是 i d = ( x − 1 ) ⋅ m + y id = (x-1) \cdot m + y i d = ( x − 1 ) ⋅ m + y vector \text{vector} vector vector [ x ] ← { y } \text{vector}[x] \leftarrow \{y\} vector [ x ] ← { y } x x x vector [ x ] \text{vector}[x] vector [ x ]
接着是查询第 x x x p p p p = l p = l p = l
接下来有一些坑点,注意到对 x x x y y y ∈ [ 1 , m − 1 ] \in [1, m-1] ∈ [ 1 , m − 1 ] p ⩾ m p \geqslant m p ⩾ m x x x
由此对 ( x , y ) (x, y) ( x , y ) 最后一列填补空缺的人的编号 n + 1 n+1 n + 1 x x x 不需要出列 ,而是填补空缺
由此程序实现需要注意的
对最后一列操作,即第 n + 1 n+1 n + 1
第一种是 s o l v e ( 1 ) solve(1) s o l v e ( 1 ) x x x vector [ n + 1 ] ← { x } \text{vector}[n+1] \leftarrow \{x\} vector [ n + 1 ] ← { x }
另外一种是 s o l v e ( 0 ) solve(0) s o l v e ( 0 ) m − 1 m-1 m − 1 ( x , y ) (x, y) ( x , y ) n + 1 n+1 n + 1 x x x 填补空缺 的,不需要真正出列,不需要将其放在 vector [ n + 1 ] \text{vector}[n+1] vector [ n + 1 ] vector [ x ] \text{vector}[x] vector [ x ]
对其他列操作,加入是 ( x , y ) (x, y) ( x , y ) x x x y y y i d id i d i d id i d n + 1 n+1 n + 1 vector \text{vector} vector vector [ n + 1 ] ← { i d } \text{vector}[n+1] \leftarrow \{id\} vector [ n + 1 ] ← { i d } n + 1 n+1 n + 1 x x x i d 2 id2 i d 2 vector [ x ] ← { i d 2 } \text{vector}[x] \leftarrow \{id2\} vector [ x ] ← { i d 2 }
这样所有信息都维护好了
如果对第 m m m x x x p p p p ⩽ n p \leqslant n p ⩽ n p p p vector [ n + 1 ] [ p − n − 1 ] \text{vector}[n+1][p-n-1] vector [ n + 1 ] [ p − n − 1 ]
如果对让 ( x , y ) (x, y) ( x , y ) x ⩽ m − 1 x \leqslant m-1 x ⩽ m − 1 y y y p p p p ⩽ m − 1 p \leqslant m-1 p ⩽ m − 1 vector [ x ] [ p − m ] \text{vector}[x][p-m] vector [ x ] [ p − m ]
珂朵莉树
珂朵莉树可以较快地实现
区间加
区间赋值
区间第 k k k
求区间 n n n
珂朵莉树特别擅长处理区间 [ l , r ] [l, r] [ l , r ] v v v < l , r , v > \left<l, r, v \right> ⟨ l , r , v ⟩ [ l , r ] [l, r] [ l , r ] v v v
对三元组按区间左端点排序
1 2 3 4 5 6 7 8 struct Node { int l, r; mutable long long v; Node(int l, int r, long long v) : l(l), r(r), v(v) {} bool operator< (const Node &rhs) const { return l < rhs.l; } };
区间分裂 < l , r , v > → < l , p o s − 1 , v > ∪ < p o s , r , v > \displaystyle \left<l, r, v\right> \to \left<l, pos-1, v \right> \cup \left<pos, r, v \right> ⟨ l , r , v ⟩ → ⟨ l , p o s − 1 , v ⟩ ∪ ⟨ p o s , r , v ⟩ 按左端点排序 ⩾ p o s \geqslant pos ⩾ p o s i t it i t
如果已经存在以 p o s pos p o s
否则,令 i t ← i t − 1 it\leftarrow it-1 i t ← i t − 1 i t it i t [ l ⋯ p o s ⋯ r ] [l\cdots pos \cdots r] [ l ⋯ p o s ⋯ r ] i t it i t < l , p o s − 1 , v > , < p o s , r , v > \left<l, pos-1, v \right>, \left<pos, r, v \right> ⟨ l , p o s − 1 , v ⟩ , ⟨ p o s , r , v ⟩
1 2 return tr.insert(Node(pos, r, v)).first返回插入的位置
区间赋值 [ l , r ] [l, r] [ l , r ] [ l , r ] [l, r] [ l , r ] < l , r , n o w > \left<l, r, now \right> ⟨ l , r , n o w ⟩
区间加 [ l , r ] [l, r] [ l , r ]
1 2 3 4 5 6 void add(int l, int r, long long v) { auto end = split(r+1); for (auto it = split(l); it != end; it++) { it->v += v; } }
区间第 k 大 [ l , r ] [l, r] [ l , r ]
1 2 auto end = split(r+1); for (auto it = split(l); it != end; it++)
这样每一次迭代器 i t it i t ( v , l e n ) (v, len) ( v , l e n ) v v v l e n len l e n vector \text{vector} vector
二元组按值 v v v k k k
1 2 3 4 for (auto u : v) { k -= u.second; if (k <= 0) return u..first; }
求区间所有数的 n 次方的和 x = power ( x , n ) x = \text{power}(x, n) x = power ( x , n )
1 2 3 4 5 6 long long sum = 0; auto end = split(r+1); for (auto it = split(l); it != end; it++) { tot = tot + power(it->v, n) * (it->r - it->l + 1); }
CF915E Physical Education Lessons n n n q q q ( l , r , k ) (l, r, k) ( l , r , k ) k = 1 k = 1 k = 1 [ l , r ] [l, r] [ l , r ] k = 2 k = 2 k = 2 [ l , r ] [l, r] [ l , r ]
算法分析 s u m = n sum = n s u m = n 1 1 1 [ l , r ] [l, r] [ l , r ] k k k split \text{split} split l e n len l e n 1 1 1 0 0 0 l e n len l e n v ⋅ l e n v \cdot len v ⋅ l e n
这样对于每一个询问可以维护出 [ l , r ] [l, r] [ l , r ] l e n len l e n
对于 k = 2 k = 2 k = 2 [ l , r ] [l, r] [ l , r ] 1 1 1 1 1 1 t o t = ∑ v ⋅ l e n tot = \sum v \cdot len t o t = ∑ v ⋅ l e n ∑ l e n − ∑ v ⋅ l e n \sum len - \sum v\cdot len ∑ l e n − ∑ v ⋅ l e n
对于 k = 1 k = 1 k = 1 1 1 1 t o t tot t o t t o t tot t o t
 微信
微信 支付宝
支付宝