KMP 算法
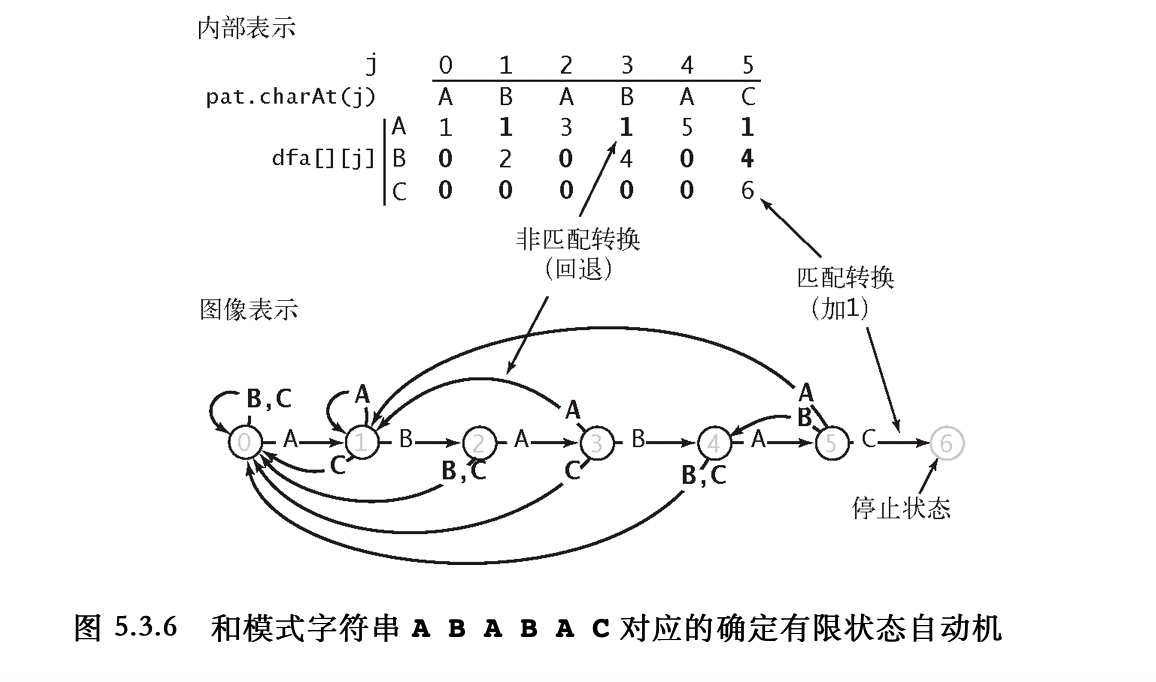
失配函数计算 ,根据之前的分析,对于某个位置 P ( i ) P(i) P ( i ) T [ ⋯ k ⋯ ] T[\cdots k \cdots] T [ ⋯ k ⋯ ] 失配 前缀子串 P [ 0 ⋯ i − 1 ] P[0 \cdots i-1] P [ 0 ⋯ i − 1 ] P P P 自己匹配自己
f ( i ) = j f(i) = j f ( i ) = j P ( i ) P(i) P ( i ) 应该跳到前缀的哪个位置 0 0 0 j j j 状态机上已经匹配了 j j j [ 0 ⋯ j − 1 ] [0\cdots j-1] [ 0 ⋯ j − 1 ] P ( i ) P(i) P ( i ) 尝试 给 P ( i ) P(i) P ( i ) P ( j ) P(j) P ( j ) f ( i ) = j f(i) = j f ( i ) = j j j j j j j 已匹配前缀 [ 0 ⋯ j − 1 ] [0\cdots j-1] [ 0 ⋯ j − 1 ] 0 0 0 尝试匹配 P ( i ) , P ( j ) P(i), P(j) P ( i ) , P ( j ) 算法设计如下,遍历 P P P P ( i ) P(i) P ( i ) j = f ( i ) j = f(i) j = f ( i )
如果 P ( j ) ≠ P ( i ) P(j) \neq P(i) P ( j ) = P ( i ) 失配边 走,即不断地令 j ′ ← f ( j ) j' \leftarrow f(j) j ′ ← f ( j ) P ( j ′ ) P(j') P ( j ′ ) P ( i ) P(i) P ( i )
如果找不到这样的 j ′ j' j ′ 0 0 0
可以发现一个递推结构 ,即进行第 i i i i + 1 i+1 i + 1
P ( i ) = P ( j ′ ) P(i) = P(j') P ( i ) = P ( j ′ ) i + 1 i+1 i + 1 j ′ + 1 j'+1 j ′ + 1 f ( i + 1 ) = j ′ + 1 f(i+1) = j'+1 f ( i + 1 ) = j ′ + 1 如果找不到这样的 j ′ j' j ′ j ′ = 0 j'=0 j ′ = 0 P ( i ) ≠ P ( j ′ ) P(i) \neq P(j') P ( i ) = P ( j ′ ) f ( i + 1 ) = j ′ f(i+1) = j' f ( i + 1 ) = j ′
有了失配函数,主算法就比较好理解了
j = 0 j = 0 j = 0 P ( 0 ) P(0) P ( 0 ) 遍历文本串 T T T T ( i ) T(i) T ( i )
如果 T ( i ) ≠ P ( j ) T(i) \neq P(j) T ( i ) = P ( j ) 不断沿着失配边 j ← f ( j ) j \leftarrow f(j) j ← f ( j )
如果 T ( i ) = P ( j ) T(i) = P(j) T ( i ) = P ( j ) j ← j + 1 j \leftarrow j+1 j ← j + 1
如果循环中 j j j 走完了模式串 ,即 j = length ( P ) j = \text{length}(P) j = length ( P ) T [ i − m + 1 , i ] T[i-m+1, i] T [ i − m + 1 , i ] i i i T T T j ≠ length ( P ) j \neq \text{length}(P) j = length ( P ) P P P
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 const int maxn = 1e5 + 10; int f[maxn]; void getFail(const char *P) { int n = strlen(P); f[0] = 0, f[1] = 0; for (int i = 1; i < n; i++) { int j = f[i]; while (j && P[j] != P[i]) j = f[j]; f[i+1] = (P[j] == P[i] ? j+1 : 0); } } vector<int> ans; void KMP(const char *T, const char *P) { int n = strlen(T), m = strlen(P); getFail(P); int j = 0; for (int i = 0; i < n; i++) { while (j && T[i] != P[j]) j = f[j]; if (T[i] == P[j]) j++; if (j == m) ans.push_back(i-m+1); } }
最短循环节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 const int maxn = 1000000 + 10; int f[maxn], n; char str[maxn]; void getFail memset(f, 0, sizeof f); for (int i = 1; i < n; i++) { int j = f[i]; while (j && str[j] != str[i]) j = f[j]; f[i+1] = (str[i] == str[j] ? j+1 : 0); } } int main freopen("input.txt" , "r" , stdin); int T = 0; while (scanf("%d" , &n) == 1 && n) { printf ("Test case #%d\n" , ++T); scanf("%s" , str); getFail(); for (int i = 2; i <= n; i++) { if (f[i] > 0 && i % (i-f[i]) == 0) printf ("%d %d\n" , i, i / (i-f[i])); } puts("" ); } }
值得注意的是,对于字符串 str [ 0 ⋯ n − 1 ] \text{str}[0\cdots n-1] str [ 0 ⋯ n − 1 ] KMP \text{KMP} KMP f ( i ) f(i) f ( i ) i ∈ [ 1 , n ] i \in [1, n] i ∈ [ 1 , n ] i i i
Trie
Trie 是基于前缀的多叉树数据结构,Trie 的构建是采用动态开点的
指针 p p p 1 1 1
Trie \text{Trie} Trie 1 1 1 在构建的时候,同时标记每个编号 为 idx \text{idx} idx end [ i d x ] \text{end}[idx] end [ i d x ]
插入 p p p 1 1 1 c c c
如果 trie ( p , c ) = q \text{trie}(p, c) = q trie ( p , c ) = q trie \text{trie} trie p ← q p \leftarrow q p ← q
如果 trie ( p , c ) = 0 \text{trie}(p, c) = 0 trie ( p , c ) = 0 trie ( p , c ) = + + t o t = q \text{trie}(p, c) = ++tot = q trie ( p , c ) = + + t o t = q p ← q p \leftarrow q p ← q
字符串扫描完成后,标记末尾节点信息 e n d ( p ) end(p) e n d ( p ) 注意,一般情况下,只在表示字符串末尾的节点,打标记
查询
同样指针 p p p 1 1 1 c c c trie ( p , c ) = 0 \text{trie}(p, c) = 0 trie ( p , c ) = 0 trie \text{trie} trie
否则的话,p = trie ( p , c ) p = \text{trie}(p, c) p = trie ( p , c )
字符串扫描完毕之后,如果 end ( p ) \text{end}(p) end ( p ) trie \text{trie} trie
前缀统计
只有在字符串末尾,cnt ( p ) ≠ 0 \text{cnt}(p) \neq 0 cnt ( p ) = 0 p p p 1 1 1 str \text{str} str cnt \text{cnt} cnt ∑ cnt ( p ) \sum \text{cnt}(p) ∑ cnt ( p )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 const int maxn = 500000 + 10; class Trie { public: int n; int tot; vector<vector<int> > t; vector<int> cnt; Trie() = default; Trie(int _n) : n(_n) { tot = 1; t.resize(n), cnt.resize(n); fill(t.begin(), t.end(), vector<int> (26, 0)); fill(cnt.begin(), cnt.end(), 0); } void insert(const string &str) { int p = 1; for (auto x : str) { int c = x - 'a' ; if (t[p][c] == 0) t[p][c] = ++tot; p = t[p][c]; } cnt[p]++; } int query(const string &str) { int p = 1, res = 0; for (auto x : str) { int c = x - 'a' ; if (t[p][c] == 0) break ; p = t[p][c]; res += cnt[p]; } return res; } }; Trie trie(maxn); int n, m; int main freopen("input.txt" , "r" , stdin); ios::sync_with_stdio(false ); cin.tie(0), cout.tie(0); cin >> n >> m; while (n--) { string str; cin >> str; trie.insert(str); } while (m--) { string str; cin >> str; int res = trie.query(str); cout << res << endl; } }
Trie 处理位运算
最大异或对 ∀ A i \forall \ A_i ∀ A i ∀ i ∈ [ highbit → lowbit ] \forall \ i \in [\text{highbit} \to \text{lowbit}] ∀ i ∈ [ highbit → lowbit ] A j A_j A j A j A_j A j 尽可能多的高位与 A i A_i A i ,这样异或的高位就有尽可能多的 1 1 1
将所有数按位插入 trie \text{trie} trie p = 1 p = 1 p = 1
遍历每个 A i A_i A i i ∈ [ highbit → lowbit ] i \in [\text{highbit} \to \text{lowbit}] i ∈ [ highbit → lowbit ]
如果 trie ( p , ! i ) ≠ 0 \text{trie}(p, !i) \neq 0 trie ( p , ! i ) = 0 trie ( p , ! i ) \text{trie}(p, !i) trie ( p , ! i ) r e s + = ( 1 < < i ) res += (1 << i) r e s + = ( 1 < < i )
否则沿着 trie ( p , i ) \text{trie}(p, i) trie ( p , i )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 const int maxn = 3100000 + 5; const int N = 1e5 + 5; int n, a[N]; class Trie { public: int tot; int t[maxn][2]; Trie tot = 1; memset(t, 0, sizeof t); } void insert(int x) { int p = 1; for (int i = 30; i >= 0; i--) { int c = (x >> i & 1); if (t[p][c] == 0) t[p][c] = ++tot; p = t[p][c]; } } int query(int x) { int res = 0, p = 1; for (int i = 30; i >= 0; i--) { int c = x >> i & 1; if (t[p][!c]) { res += (1<<i); p = t[p][!c]; } else p = t[p][c]; } return res; } }; Trie trie; int main() { freopen("input.txt", "r", stdin); scanf("%d", &n); for (int i = 0; i < n; i++) { scanf("%d" , &a[i]); trie.insert(a[i]); } int res = 0; for (int i = 0; i < n; i++) res = max(res, trie.query(a[i])); printf ("%d\n" , res); }
该问题也有扩展版本最长异或值路径 ( x , y ) (x, y) ( x , y ) d ( y ) d(y) d ( y ) y y y d ( y ) = d ( x ) ⊕ e ( x , y ) d(y) = d(x) \oplus e(x, y) d ( y ) = d ( x ) ⊕ e ( x , y ) 0 0 0 ⊕ ( x → y ) \oplus (x \to y) ⊕ ( x → y ) d ( x ) ⊕ d ( y ) d(x) \oplus d(y) d ( x ) ⊕ d ( y ) dfs \text{dfs} dfs d [ x ] d[x] d [ x ]
Trie 处理字符串统计
Remember The Word
令 f ( i ) f(i) f ( i ) S [ i ⋯ L ] S[i\cdots L] S [ i ⋯ L ] i i i
f ( i ) = ∑ f ( j ) { S [ i ⋯ j − 1 ] 构成一个合法的单词 } f(i) = \sum f(j) \quad \{ S[i \cdots j-1] \text{构成一个合法的单词} \}
f ( i ) = ∑ f ( j ) { S [ i ⋯ j − 1 ] 构成一个合法的单词 }
从而考虑可以把所有的单词插入 trie \text{trie} trie
f ( i ) = ∑ f ( ( i + l e n ( x ) − 1 ) + 1 ) { x 是满足 S [ i ⋯ ] ∈ trie 的单词 } f(i) = \sum f((i + len(x)-1) + 1) \quad \{x \ \text{是满足} \ S[i\cdots] \in \text{trie} \ \text{的单词} \}
f ( i ) = ∑ f ( ( i + l e n ( x ) − 1 ) + 1 ) { x 是满足 S [ i ⋯ ] ∈ trie 的单词 }
将所有单词插入 trie \text{trie} trie l e n [ ⋯ ] len[\cdots] l e n [ ⋯ ]
具体来说,i i i i i i
在 trie \text{trie} trie p = 1 p=1 p = 1 S [ i ⋯ ] S[i\cdots] S [ i ⋯ ] l e n ( p ) len(p) l e n ( p ) vec \text{vec} vec
对每一个 i i i vec \text{vec} vec f ( i ) + = f ( i + vec ( j ) ) f(i) += f(i + \text{vec}(j)) f ( i ) + = f ( i + vec ( j ) ) f ( l e n ) = 1 f(len) = 1 f ( l e n ) = 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 const int maxn = 1200000 + 5, mod = 20071027; const int N = 300000 + 10; string S; int n, len; ll f[N]; class Trie { public: int t[maxn][26]; int len[maxn]; int tot = 1; Trie tot = 1; memset(len, 0, sizeof len); memset(t, 0, sizeof t); } void clear tot = 1; memset(t, 0, sizeof t); memset(len, 0, sizeof len); } void insert(const string &str) { int p = 1; for (auto x : str) { int c = x-'a' ; if (!t[p][c]) t[p][c] = ++tot; p = t[p][c]; } len[p] = str.length(); } void query(const string &str, int pos, vector<int> &vec) { int p = 1; for (int i = pos; i < str.length(); i++) { int c = str[i] - 'a' ; if (t[p][c] == 0) break ; p = t[p][c]; if (len[p]) vec.push_back(len[p]); } } }; Trie trie; void dp memset(f, 0, sizeof f); len = S.length(); f[len] = 1; for (int i = len-1; i >= 0; i--) { vector<int> vec; trie.query(S, i, vec); for (auto x : vec) f[i] += f[i+x], f[i] %= mod; } printf ("%lld\n" , f[0]); } int main freopen("input.txt" , "r" , stdin); ios::sync_with_stdio(false ); cin.tie(0), cout.tie(0); int T = 0; while (cin >> S) { trie.clear(); printf ("Case %d: " , ++T); cin >> n; for (int i = 0; i < n; i++) { string str; cin >> str; trie.insert(str); } dp(); } }
Trie 与前缀处理
Trie 这种数据结构经常用于前缀比较问题strcmp() Anyone
这里可以使用边插入边统计,对于第 i i i S S S trie \text{trie} trie [ 1 ⋯ i − 1 ] [1\cdots i-1] [ 1 ⋯ i − 1 ] trie \text{trie} trie p p p S j S_j S j t ( p , S j ) = 0 t(p, S_j) = 0 t ( p , S j ) = 0 p p p cnt = 2 ⋅ lcp + 1 \text{cnt} = 2 \cdot \text{lcp} + 1 cnt = 2 ⋅ lcp + 1 2 ⋅ ∑ lcp + 1 ⋅ ( i − 1 ) 2 \cdot \sum \text{lcp} + 1\cdot (i-1) 2 ⋅ ∑ lcp + 1 ⋅ ( i − 1 ) lcp \text{lcp} lcp 2 2 2 i i i i − 1 i-1 i − 1 i − 1 i-1 i − 1
因为串在 S j S_j S j S [ j ⋯ ’0’ ] S[j \cdots \text{'0'}] S [ j ⋯ ’0’ ] i i i r e s ← r e s + ( i − 1 ) res \leftarrow res + (i-1) r e s ← r e s + ( i − 1 )
如果两个串完全相同,那么相当于额外花费了失配补全代价 ,即把原先失配的部分,让它匹配上[ 1 ⋯ i ] [1\cdots i] [ 1 ⋯ i ] i i i r e s ← r e s + ( i − 1 ) res \leftarrow res + (i-1) r e s ← r e s + ( i − 1 ) i − 1 i-1 i − 1 i − 1 i-1 i − 1 r e s ← r e s + 2 ⋅ ( i − 1 ) res \leftarrow res + 2\cdot (i-1) r e s ← r e s + 2 ⋅ ( i − 1 )
可以设计算法如下
边插入边统计,对于第 i i i r e s ← r e s + ( i − 1 ) res \leftarrow res + (i-1) r e s ← r e s + ( i − 1 )
对于 trie \text{trie} trie p p p cnt ( p ) \text{cnt}(p) cnt ( p ) [ 1 ⋯ i − 1 ] [1\cdots i-1] [ 1 ⋯ i − 1 ] p p p 2 cnt ( p ) , r e s + = 2 ⋅ cnt ( p ) 2 \text{cnt}(p), \quad res += 2\cdot \text{cnt}(p) 2 cnt ( p ) , r e s + = 2 ⋅ cnt ( p ) cnt ( p ) + + \text{cnt}(p)++ cnt ( p ) + +
到达串结尾的时候,还要维护一个 end ( p ) \text{end}(p) end ( p ) 补全失配的代价 ,此时意味着串相等end ( p ) \text{end}(p) end ( p ) p p p [ 1 ⋯ i − 1 ] [1\cdots i-1] [ 1 ⋯ i − 1 ] [ 1 ⋯ i − 1 ] [1\cdots i-1] [ 1 ⋯ i − 1 ] i i i 需要失配补全的串 ,此时 res + = end ( p ) \text{res} += \text{end}(p) res + = end ( p ) end ( p ) + + \text{end}(p)++ end ( p ) + +
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 const int maxn = 4001 * 1000 + 5; int n; inline int get(char x) { if (isdigit(x)) return x - '0' ; else if (isupper(x)) return x - 'A' + 10; else return x - 'a' + 36; } class Trie { public: int t[maxn][65]; int cnt[maxn], end[maxn]; int tot; Trie tot = 1; memset(t, 0, sizeof t); memset(cnt, 0, sizeof cnt); memset(end, 0, sizeof end); } void clear tot = 1; memset(t, 0, sizeof t); memset(cnt, 0, sizeof cnt); memset(end, 0, sizeof end); } void insert(const string &str, int val, ll &res) { res += val; int p = 1; for (auto x : str) { int c = get(x); if (!t[p][c]) t[p][c] = ++tot; p = t[p][c]; res += 2ll*cnt[p], cnt[p]++; } res += (ll)end[p], end[p]++; } }; Trie trie; int main freopen("input.txt" , "r" , stdin); int T = 0; while (scanf("%d" , &n) == 1 && n) { printf ("Case %d: " , ++T); // init trie.clear(); string str; ll res = 0; for (int i = 1; i <= n; i++) { cin >> str; trie.insert(str, i-1, res); } printf ("%lld\n" , res); } }
Trie 计数问题
Gym10085D
考虑两个字符串 S 1 , S 2 S_1, S_2 S 1 , S 2 trie 1 \text{trie}_1 trie 1 trie 2 \text{trie}_2 trie 2 trie 1 \text{trie}_1 trie 1 t o t 1 tot_1 t o t 1 t o t 1 − 1 tot_1-1 t o t 1 − 1 不同的非空前缀 t o t 2 − 1 tot_2 - 1 t o t 2 − 1 不同的非空后缀 r e s = ( t o t 1 − 1 ) ⋅ ( t o t 2 − 1 ) res = (tot_1 - 1) \cdot (tot_2 - 1) r e s = ( t o t 1 − 1 ) ⋅ ( t o t 2 − 1 )
下面考虑重复的情况S = S 1 + c + S 2 S = S_1 + c + S_2 S = S 1 + c + S 2 trie 1 \text{trie}_1 trie 1 trie 2 \text{trie}_2 trie 2 ⩾ 3 \geqslant 3 ⩾ 3 S 1 + c + S 2 S_1 + c + S_2 S 1 + c + S 2
问题转换为,原字典集合中,有多少个长度 ⩾ 3 \geqslant 3 ⩾ 3 S 1 + c + S 2 S_1 + c + S_2 S 1 + c + S 2
cnt 1 ( c ) \text{cnt}_1(c) cnt 1 ( c ) c c c cnt 2 ( c ) \text{cnt}_2(c) cnt 2 ( c ) c c c
于是可以边插入边维护,根节点的深度假设为 d = 0 d = 0 d = 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 const int maxn = 400000 + 10; const int N = 10000 + 10; string str[N]; int n, vis[27]; class Trie { public: int t1[maxn][27], t2[maxn][27]; int cnt1[27], cnt2[27]; int tot1, tot2; Trie tot1 = tot2 = 1; memset(t1, 0, sizeof t1); memset(t2, 0, sizeof t2); memset(cnt1, 0, sizeof cnt1); memset(cnt2, 0, sizeof cnt2); } void insert(const string &str) { int p = 1; for (int i = 0; i < str.length(); i++) { int c = str[i] - 'a' ; if (!t1[p][c]) { if (i) cnt1[c]++; t1[p][c] = ++tot1; } p = t1[p][c]; } p = 1; for (int i = str.length()-1; i >= 0; i--) { int c = str[i] - 'a' ; if (!t2[p][c]) { // todo if (i != str.length()-1) cnt2[c]++; t2[p][c] = ++tot2; } p = t2[p][c]; } } ll query ll res = 0; res += 1ll * (tot1 - 1) * (tot2 - 1); for (int i = 0; i < 26; i++) res -= 1ll * cnt1[i] * cnt2[i]; return res; } } trie; int main freopen("dictionary.in" , "r" , stdin); freopen("dictionary.out" , "w" , stdout); ios::sync_with_stdio(false ); cin.tie(0), cout.tie(0); memset(vis, 0, sizeof vis); cin >> n; for (int i = 1; i <= n; i++) { cin >> str[i]; trie.insert(str[i]); } ll res = 0; for (int i = 1; i <= n; i++) { const auto &S = str[i]; if (S.length() == 1 && vis[S[0] - 'a' ] == 0) { vis[S[0] - 'a' ] = 1, res++; } } res += trie.query(); cout << res << endl; }



 微信
微信 支付宝
支付宝